
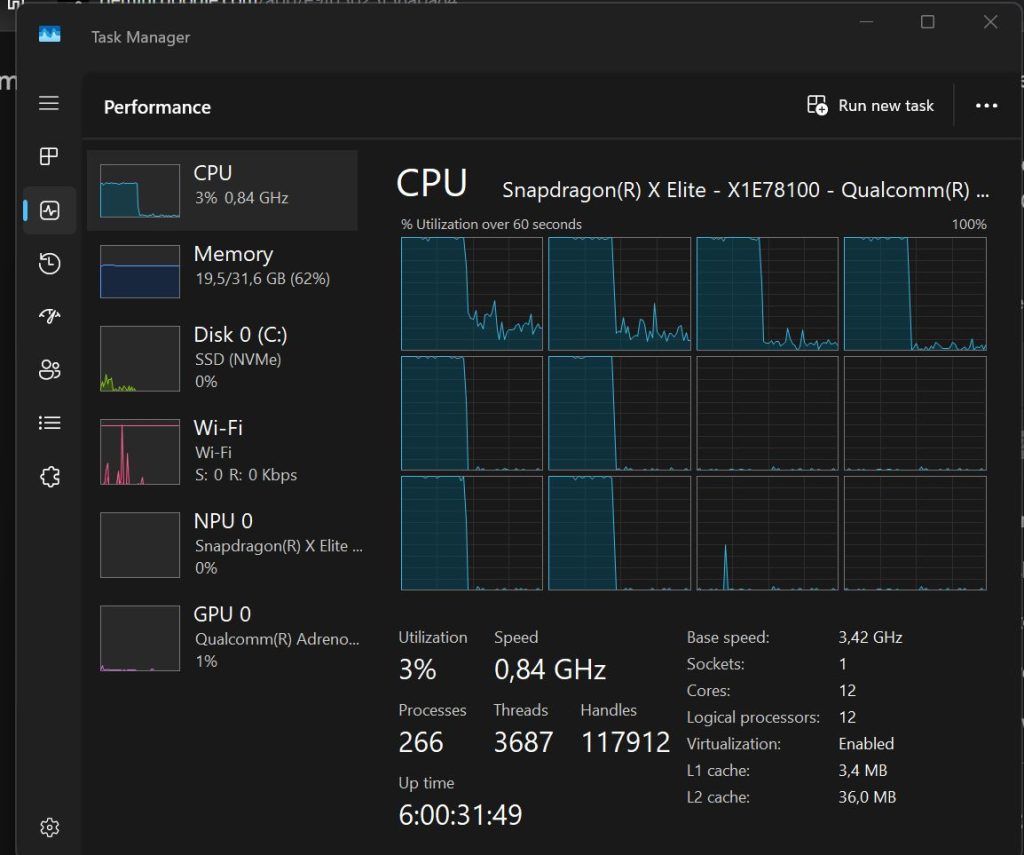
Pemntru că am văzut că noul model LLM Gemma4 lansat de Google poate fi folosit local (complet offline), ca să beneficiezi de AI pe smartphone, am zis că merită să văd cum va funcționa el pe un Asus Vivobook S15 Copilot PC cu Windows 11 on ARM și 32GB RAM, sperând că pot pune în valoare NPU-ul ridicat atâta în slăvi de către Microsoft. Din păcate nu merge (încă!) pe NPU, însă se descurcă rulat pe CPU.
Dar poate platforma Snapdragon X Elite (lansată acum 2 ani) să ofere performanțe măcar la egalitate cu cipsetul Snapdragom SM8850-AC Elite Gen 5 (3 nm) disponibil pe cele mai noi flagship-uri de la Samsung sau Xiaomi? Și rezultatul m-a surprins.
Cum rulezi Gemma4 local pe Asus Vivobook S15 Copilot+ PC cu Windows on ARM?
Prima chestie pe care a trebuit să o fac este să găsesc o soluție de a rula local Gemma4 pe Windows 11 on ARM. După ce m-am documentat puțin am ajuns la concluzia că nu merge prin AnythingLLM via NPU, nu merge nici prin Microsoft Foundry via VS Code, tot pe NPU, însă merge pe CPU dacă folosesc Ollama.
M-am desumflat rapid când am înțeles că nu am cum să mă folosesc de NPU pe un sistem Windows 11 on ARM Copilot și nici măcar pe GPU, singura consolare era că speram că o să se miște măcar acceptabil pe CPU.
Dai fuga pe site la Ollama, descarci executabilul (din păcate nu e optimizat pentru Windows 11 on ARM) și îl instalezi. Apoi descarci ce model Gemma4 vrei.
Am mers direct pe varianta Gemma4:e2b, cea care în teorie îmi permitea cea mai bună experiență – Ollama oferă acces direct la acest model, trebuie doar să îl selectezi din interfață și să aștepți să se descarce și să se instaleze. Pe urmă îl poți folosi, fie via API, fie în interfață, fie în mod CLI.
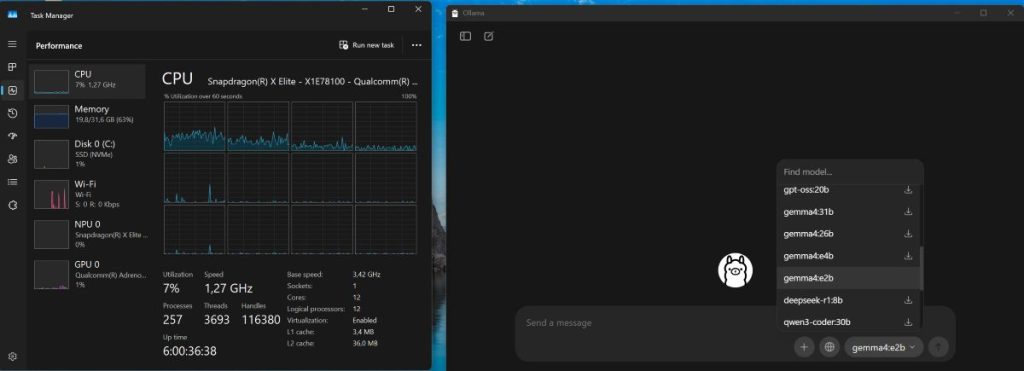
I-am dat drumul în interfață ca să văd cum merge și … a fost decent. Pentru o conversație cu AI s-a descurcat chiar bine, cu toate că procesorul își duce toate core-urile spre 100% aproape instant.
Următorul pas a fost să văd dacă face față cu un OpenCode în docker – o dorință mult prea optimistă pentru că după mai mult de 20 de minute de procesat, nu a putut să îmi dea nici măcar un răspuns la o problemă simplă de Hello World în Python.
Asta a fost momentul în care am renunțat și am zis că poate nu ar fi rău să îi fac un benchmark și să văd cam cum stă treaba.
Gemma4 pe Windows on ARM cu Snapdragon X Elite
Și a venit momentul adevărului … 16.21 tokens/s, pe Gemma4:e2b. Puteți testa și voi folosind următoarea comandă în PowerShell:
ollama run gemma4:e2b --verboseȘi apoi îi dați ce prompt doriți.
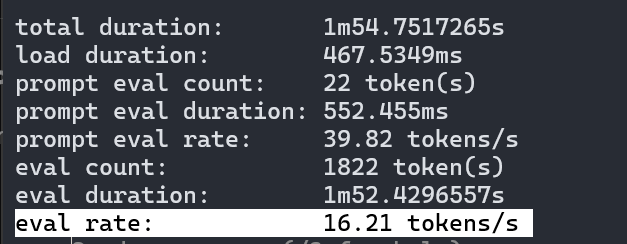
Recunosc că mă așteptam la mai mult, măcar la o valoare dublă. 16.21 – 19.33 tokens pe secundă e o valoare mică, să zicem suficientă pentru operații simple de chat care să implice generare de text, analiză de text etc. Însă nu pentru sarcini complexe și sub nicio formă cu o altă aplicație care să consume putere de procesare în fundal pentru că posibil să ajungeși să nu mai puteți folosi PC-ul.
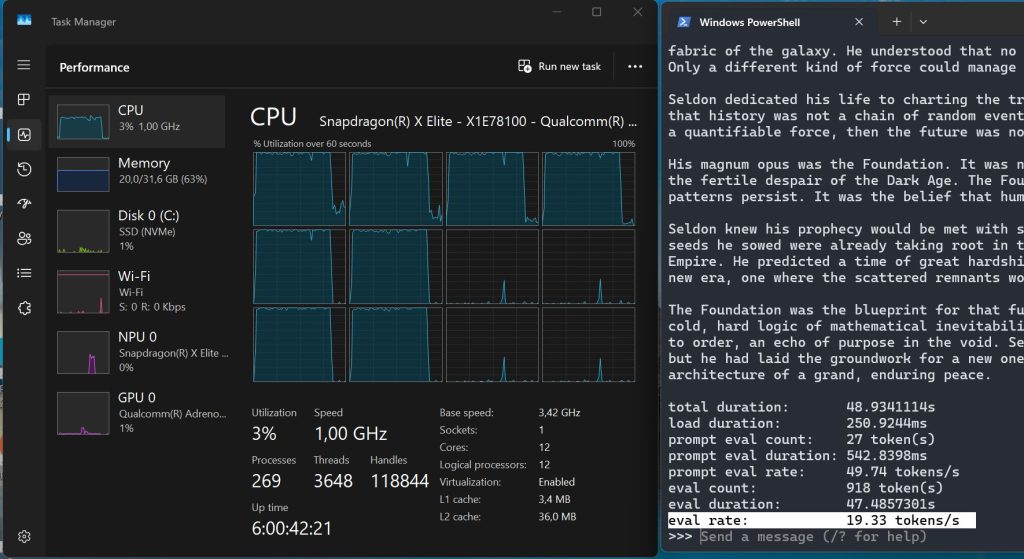
Cu alte cuvinte, Gemma4:e2b merge local fără pretenții. Mi-am adus aminte că acum 25 de ani, când mă jucam pe PC-uri cu AMD/Intel și începusem să prind gust de 3D cu plăcile 3Dfx și Banshee, mă bucuram dacă puteam să joc ceva (F1 de exemplu) undeva la 15-20 fps. Cam același sentiment l-am avut și acum cu Gemma4 local.
Cum merge Gemma4 pe un flagship Android?
Și dacă tot am pornit pe drumul ăsta în care m-am jucat cu Gemma4 și încă testez Xiaomi 17 Ultra și Samsung Galaxy S26 Ultra, mi-a fost clar că trebuie să măsor și cum se mișcă AI-ul cu Gemma4 pe ele.
Folosind Google AI Edge Gallery am descărcat modelele Gemma4 e2b și e4b pe Xiaomi 17 Ultra și le-am pus la un test care a spus următoarele:
| Model | CPU (tokens/s) | GPU (tokens/s_ |
| Gemma4:e4b | 6.17 | 16.16 |
| Gemma4:e2b | 16.10 | 39.32 |
Pe e4b am mers în test cu 1500 tokens pentru prefill, iar pentru e2b doar cu 512 (ca să se termine mai repede testul):
În traducere, situația stă în felul următor: dacă alegeți modeul cu 2 miliarde de parametrii, pe GPU, Xiaomi 17 Ultra merge excepțional, cu aproape 40 tokens pe secundă (dacă și pe Windows on ARM Gemma4 ar fi mers la fel, era super bine), iar pe CPU e la 16 tokens. Cam aceleași date le-am obținut cu AI Edge Gallery și pe iPhone 16 Pro, unde am avut 34.38 tokens/s ăe GPU și 32.72 tokens/s în CPU.
Pe modelul cu 4 miliarde de parametrii, performanța e la sub jumătate și pe CPU și pe GPU, dar încă folosibil pentru sarcini simple. Practic pot să spun că Gemma4 e4b merge pe un flagship Android curent (în GPU) cu aceiași viteză cu care funcționează Gemma4 e2b pe un Copilot PC cu Snapdragon X Elite, dar pe CPU.
De reținut că și pe CPU și pe GPU, smartphone-urile Android se incing semnificativ și bateria scade vertiginos. Iar pe PC-ul Copilot, CPU-ul se duce rapid în 100% pentru aproape toate cele 12 core-uri și are un impact major în funcționare, orice alte aplicații de pe lângă Ollama se vor mișca îngrozitor de încet.
Concluzie: merge, dar cam atât
În concluzie, dacă vreți să vă jucați local cu Gemma4 pe un PC Copilot cu Windows 11 on ARM trebuie să știți că nu merge nici pe NPU, nici pe GPU (cel puțin acum) și îl puteți folosi doar pe CPU. Unde consumă CPU-ul și aduce valoare limitată.
Și nicidecum nu poate face față unor sarcini complexe, în special cele programare împreună cu OpenCode.
Pe de altă parte, dacă aveți un flagship modern (că e Android sau iOS), vă puteți juca în voie cu el pe GPU, unde cele aproape 40 tokens/secundă vă oferă o experiență foarte bună. E și normal, Google a optimizat Gemma4 e2b pentru a putea fi folosit local, pe smartphone. Doar că suge bateria la greu.


Am 54.83 tokens pe Macbook Pro 16 cu M1 Pro